
Your Brain Is Lying To You About Probability
There's always extra mental math when you consume data.
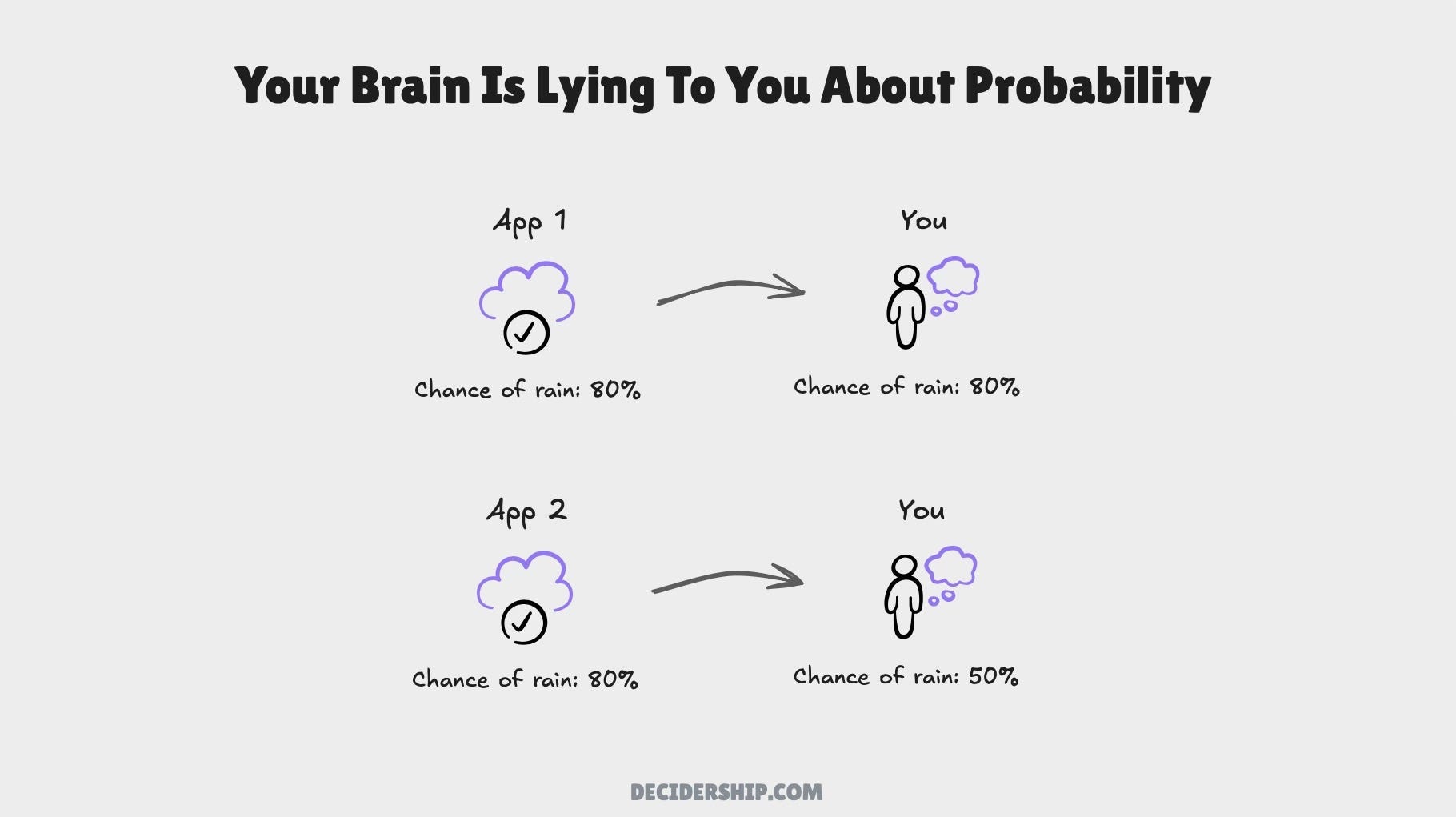
When a news app says there is a 73 percent chance a candidate will win the election, you see just one number. But there are actually two numbers you are processing. The first is the probability they’re stating. The second is how much you trust that probability. These are two separate uncertainties you are processing, and it’s good decision process to deal with both explicitly.
But we tend to merge these into one number in our head. So the number we actually end up using as an input into our decision has often been adjusted unconsciously. Our brain lies to us about probability.
We develop this over time through repeated interactions with sources. We learn naturally that not everything we consume deserves equal weight. The first time a news channel gives you a percentage, you might take it at face value. By the fourth or fifth election cycle, you change the number they give you. You make an adjustment based on how that channel has performed before.
You build a kind of credibility discount system. You multiply the data given to you by a ‘credibility weight’. So the final number in your head is something like source data X source credibility. A source with a strong track record might just have a weight close to 1 (i.e. you take the data at face value). A source you’ve learned to distrust might be 0.5 (effectively halving how believable it is).
In other words, there are always two probabilities being processed:
The first, a probability prediction of the event (e.g. there is 80% chance of rain today).
The second, the probability of that prediction (i.e. what is the predictions credibility?).
The problem is we often do this second part implicitly when we would be better off making it explicit.
It is interesting to think about how this works when we interact with AI.
First, we have a bias towards believing fluency correlates with reliability. A well-structured argument is generally thought to be believable. Humans commonly mistake how certain something is for how likely it is to be right. But AI will produce confident output regardless of the strength of the underlying answer. This means the signal we would normally use to detect uncertainty is largely absent (e.g. hesitation, qualification, hedging, etc.).
Second, the track record is not tied to a single source (e.g. person or an institution). In fact, it isn’t obvious what it would be tied to. The model provider (e.g. OpenAI / Anthropic)? The specific model (e.g. Opus 4.8)? Even if you can resolve that, the technology itself is essentially multiple sources presenting as one. It is probabilistic by design so it isn’t obvious what the measurement criteria should be. All of this makes it difficult to build a stable track record.
Regardless of what data source you’re interacting with, it is good decision process to make the second number explicit.
Two things to think about when making a credibility estimate explicit:
First, the track record mentioned above. Check the evidence for how accurate this source has been over time. Remember to make sure you are evaluating the track record in the specific domain. When a news site gives you a weather forecast, you should care about how accurate that news site has been for predicting the weather.1
Second, like most decisions, your effort should scale with the cost of being wrong. None of this really matters for small decisions. It is not worth spending the cognitive effort to do this when the stakes are low. When the decision is important, that’s when you should always be making the source credibility explicit.
This week, pick one information source you interact with regularly. The next time you get some information from it, spend some time explicitly thinking about the credibility question: how much do I usually weight this? How much should I weight this?
You want to be domain-specific in your comparisons. A news site’s track record in other areas (e.g. inaccurate sensationalist reporting) does not necessarily mean that their weather predictions might be less accurate. In certain situations, track record in other domains might be a useful proxy but you should only be doing this kind of non-domain-specific comparison if you have good reason to believe the accuracy should transfer.